lab4 pytorch
lab4 pytorch基础实验
-
pytorch入门
-
task1-2 线性回归
- 闭式解、梯度下降
-
task3-4 sklearn入门
- SVC、KMeans、DBScan
- PCA、tSNE
pytorch入门
conda
环境管理
# 创建一个新环境
conda create -n myenv python=3.10
# 激活环境
conda activate myenv
# 退出当前环境
conda deactivate
# 列出已有的环境
conda env list
# 删除环境
conda remove -n myenv --all
# 查看目录
conda info --envs
# 指定安装目录
conda create --prefix ~/projects/ml-lab/env python=3.10
conda activate ~/projects/ml-lab/env
包管理
# 安装包(推荐带上频道)
conda install numpy -c conda-forge
# 移除包
conda remove numpy
# 更新包
conda update numpy
# 查看当前环境已安装的包
conda list
环境导出复制
# 导出环境配置为 YAML 文件
conda env export > environment.yml
# 从 YAML 文件创建环境
conda env create -n new-env -f environment.yml
# 克隆环境
conda create --name new-env --clone old-env
配置文件
.condarc .zshrc -> conda initialize
数据集操作
# 加载数据
iris = datasets.load_iris()
# 拆分数据
# 如果已经二维,则可以省略
X = iris.data[:, :2]
y = iris.target
lab4 task1-2 pytorch线性回归
线性回归闭式解的推导
线性回归模型
$$ \hat{y} = X \omega + b $$ 其中:
- $X \in \mathbb{R}^{n \times d}$:样本矩阵,$n$个样本,一个样本$d$个特征
- $\vec\omega \in \mathbb{R}^{d}$:权重向量
- $b \in \mathbb{R}$:偏置标量
- $\vec y \in \mathbb{R}^{n}$:目标值向量
目标:求参数 $\vec\omega$ 和 $b$ ,最小化均方误差损失:
$$ J(\vec\omega, b) = \frac{1}{2n} | X \vec\omega + b \vec 1 - \vec y |^2 $$ 其中$ \vec{1} \in \mathbb{R}^n $是全 1 的列向量,$| \vec x |^2$ = $\sum x_i^2$。
总结
显式偏置法 $$ \boxed{ \begin{aligned} \omega &= (X^\top X)^{-1} X^\top (y - b \mathbf{1}) \ b &= \frac{1}{n} \mathbf{1}^\top (y - X\omega) \end{aligned} } $$ 增广向量法 $$ \boxed{ \theta = \begin{bmatrix} b \ \omega \end{bmatrix} = \left( X’^\top X’ \right)^{-1} X’^\top y } \ X’ = [\mathbf{1} \quad X] $$
第一种推导方式更符合最小二乘法的推广和求无条件极值的思路,第二种不够直观但计算更简单,也更符合线性代数的思维方式,具体实现中我们也采用第二种方式。
梯度下降解法的推导
伪代码
def GradientDescent $(X,\ y,\ 学习率\eta,\ 迭代次数n )$ $初始化 \omega 为d维随机向量$ $初始化 b = 0$ for iter in range($n):$ $y_{预测} = X \omega + b$ $e_{误差} = y_{预测} - y$ $\$ $\nabla \omega = \frac{1}{n} X^T e_{误差}$ $\nabla b = \frac{1}{n} \sum(e_i) $ $\$ $\omega = \omega - \eta \nabla \omega$ $b = b - \eta \nabla b$ return $\omega, b$
实现
二维版本
闭式解
def lr_cf(X_list, Y_list):
w = 2
b = 4
X = torch.tensor(X_list, dtype=torch.float32).view(-1, 1) # [n, 1]
Y = torch.tensor(Y_list, dtype=torch.float32).view(-1, 1) # [n, 1]
n = X.shape[0]
# Step 1: 添加一列偏置项
ones = torch.ones(n, 1)
X_aug = torch.cat([ones, X], dim=1) # shape: [n, d+1]
# Step 2: 显式计算闭式解
XT_X = X_aug.T @ X_aug # (d+1, d+1)
XT_Y = X_aug.T @ Y # (d+1, 1)
theta = torch.inverse(XT_X) @ XT_Y # 闭式解
b = theta[0].item()
w = theta[1:].view(-1)
return w, b
梯度下降
def lr_gradient_descent(X_list, Y_list):
w = 0.1
b = 3
lr=0.01
num_iters=100
X = torch.tensor(X_list, dtype=torch.float32).view(-1, 1) # [n, 1]
Y = torch.tensor(Y_list, dtype=torch.float32).view(-1) # [n]
n = X.shape[0]
w = torch.randn(1, dtype=X.dtype)
b = torch.tensor(0.0, dtype=X.dtype)
for _ in range(num_iters):
y_pred = X @ w + b # shape: [n]
error = y_pred - Y # shape: [n]
grad_w = (1 / n) * (X.T @ error) # shape: [1]
grad_b = (1 / n) * error.sum() # scalar
w = w - lr * grad_w
b = b - lr * grad_b
return w.item(), b.item()
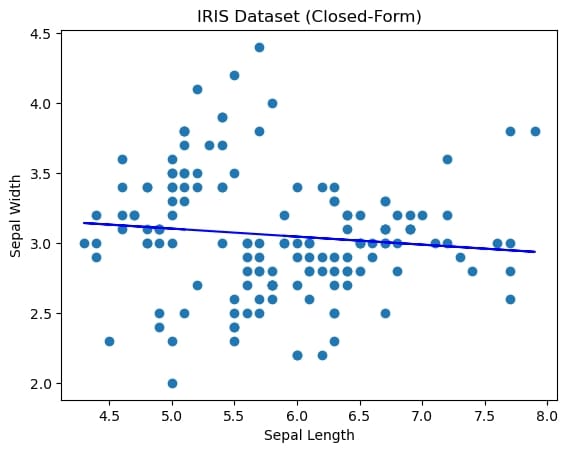
效果
闭式解运行效果
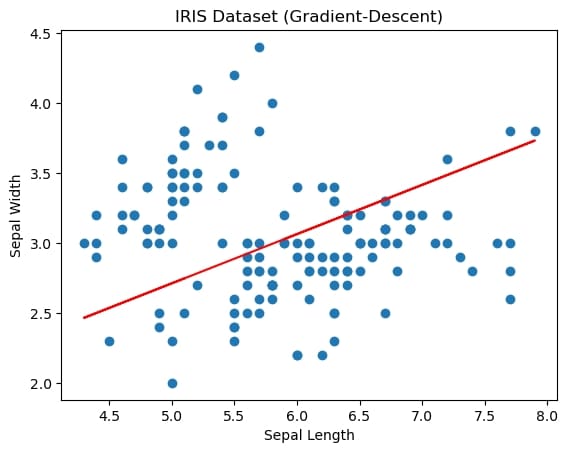
不同学习率
我们用学习率控制梯度下降时每次迭代的步长。如果步长过大,则会发生震荡甚至溢出,表现为画不出图象;如果步长过小,则收敛极慢,无法快速收敛到闭式解。在notebook中调整不同学习率并和闭式解的图象比较,验证发现确实如此。
学习率适中,lr=0.02
学习率过小,lr=0.00000001
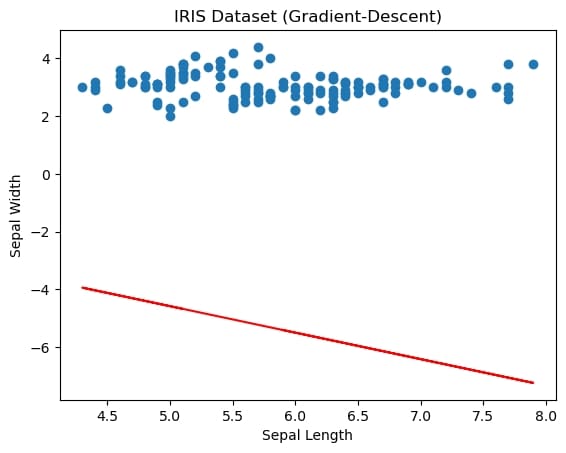
学习率过大,lr=10
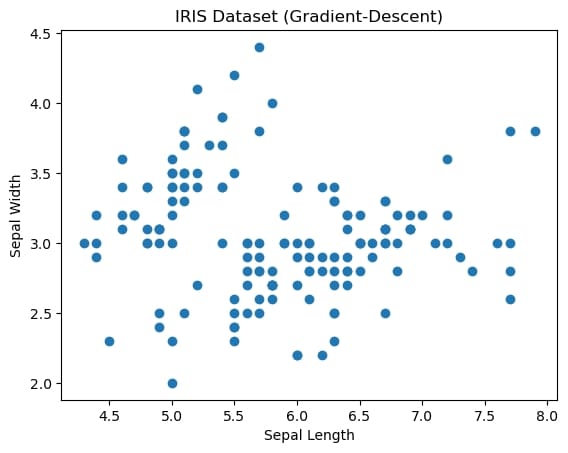
lab4 task3-4 sklearn入门
SVM分类器
导包
from sklearn import svm
调用
clf = svm.SVC(
kernel="linear",
C=1.0
)
- 超参数C
- SVM正则化参数
- C越大,越过拟合
- C>0
- kernel
- 选择svm内核算法
- 'linear': 只会画线性边界
- 'rbf': 高斯径向基,更灵活
拟合与输出
model = clf.fit(X, y)
此时的model就是svc对象,是一个分类器。
可视化
from sklearn.inspection import DecisionBoundaryDisplay
# sklearn提供的可视化决策边界
ax = plt.subplots(1, 1)
disp = DecisionBoundaryDisplay.from_estimator(
clf, # 分类器
X, # 输入数据
response_method="predict", # 使用预测数据
cmap=plt.cm.coolwarm, # 颜色
alpha=0.8, # 透明度
ax=ax, # 指定坐标轴
xlabel=iris.feature_names[0], # 横轴标签
ylabel=iris.feature_names[1], # 纵轴标签
)
调参
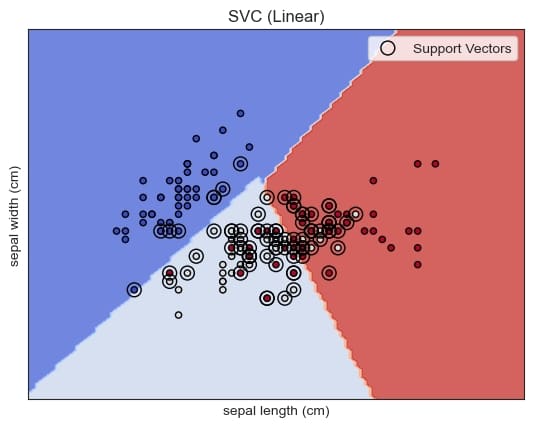
linear时的图象
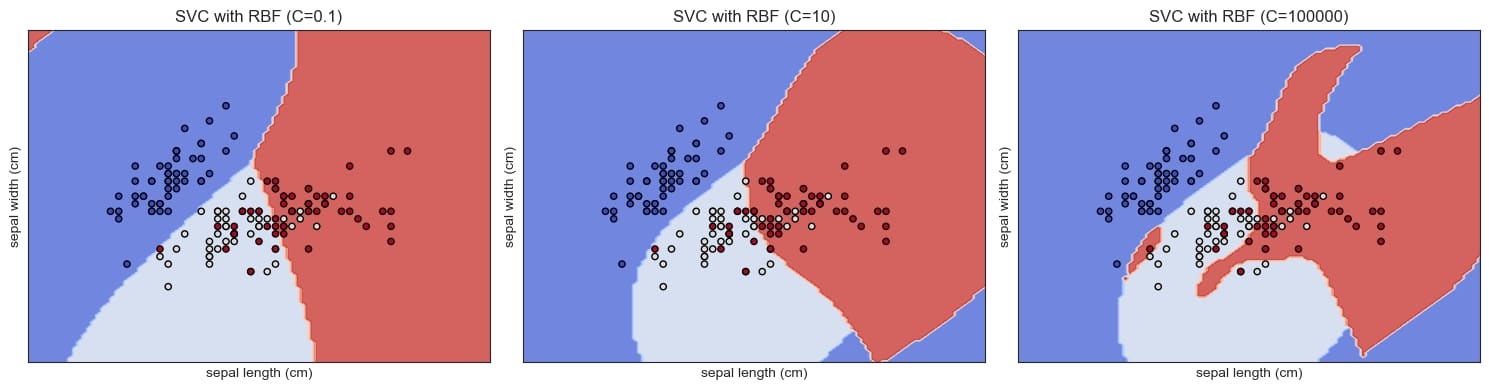
rbf时的图象,比较了三种C对拟合效果的影响
聚类-KMeans
导包
from sklearn.cluster import KMeans
调用
kms = KMeans(
n_clusters=3, # 聚类数量,默认8
n_init='auto', # 不同种子运行kmeans的轮数
random_state= 1 # 种子的大致位置
)
- n_clusters:聚类数
- 指定聚类的数量
- 默认8
- n_init:轮数
- 默认
'auto' - 随机出n_init个不同种子运行kmeans的轮数
- 这是为了尽量避免局部最优
- 默认
- random_state:种子
- 生成地图用的种子
拟合与输出
kms.fit(X)
Y=kms.labels_
kms.labels_是一个标签集合,展示了聚类结果。
可视化
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.show()
指定c=Y即用kmeans的结果给散点染色。
调参
kmeans的可操纵性一般,主要就是选择不同的种子会让聚类形态有所改变,不好人为干预算法。
聚类-DBScan
导包
from sklearn.cluster import DBSCAN
调用
dbs=DBSCAN(
eps=0.05,
min_samples=5
)
- eps:最大邻居距离
- 认定为同一聚类的两点间的最大距离
- 通过调整这个参数,可以人为控制两个聚类间的距离,实现精确聚类
- min_samples:最小人数
- 认定为一个聚类的最小样本数
- 可以筛选掉一些噪音
拟合与输出
dbs.fit(X)
Y=dbs.labels_
和kmeans一样,输出一个标签组。
可视化
plt.scatter(X[:, 0], X[:, 1], c=Y)
plt.show()
调参
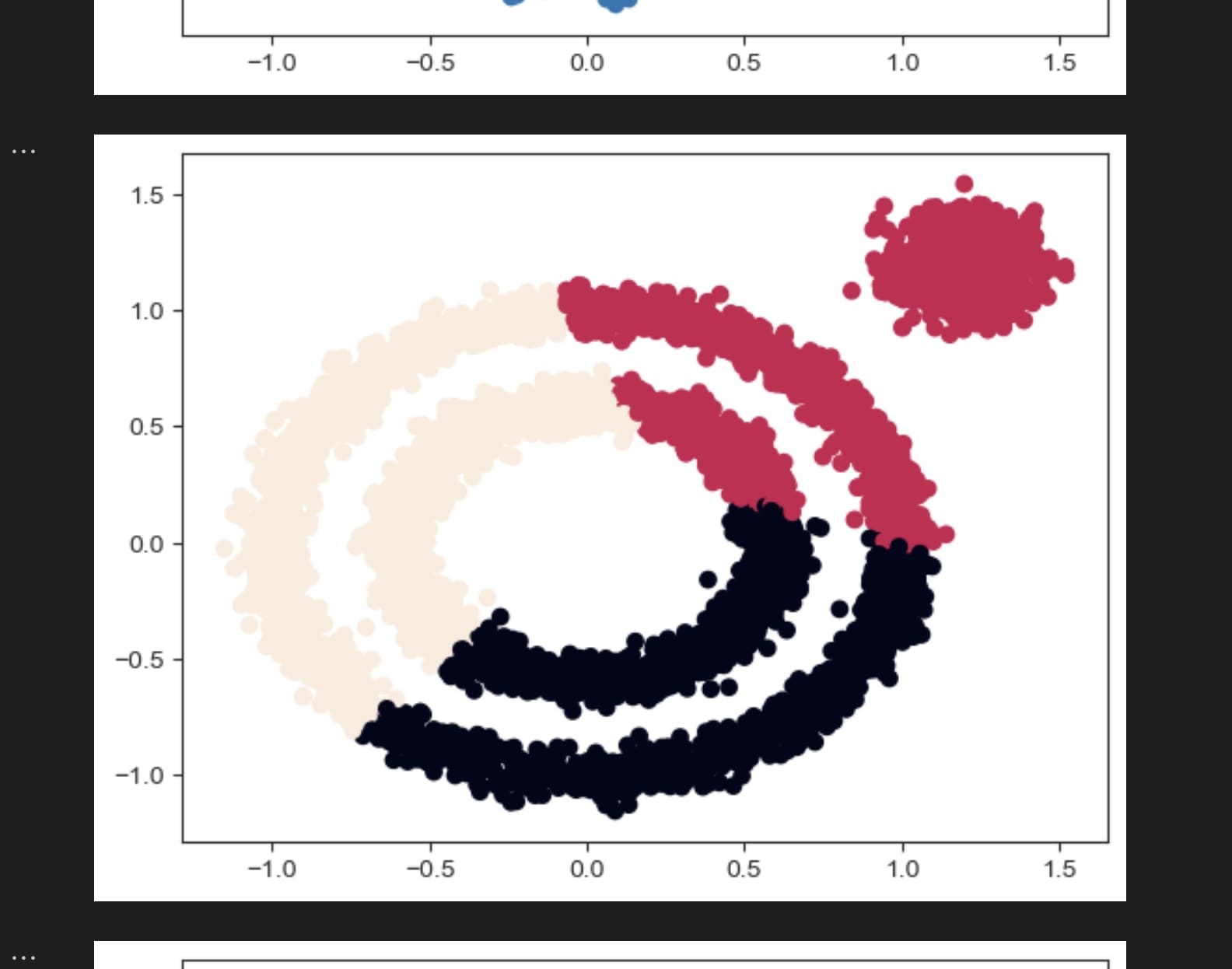
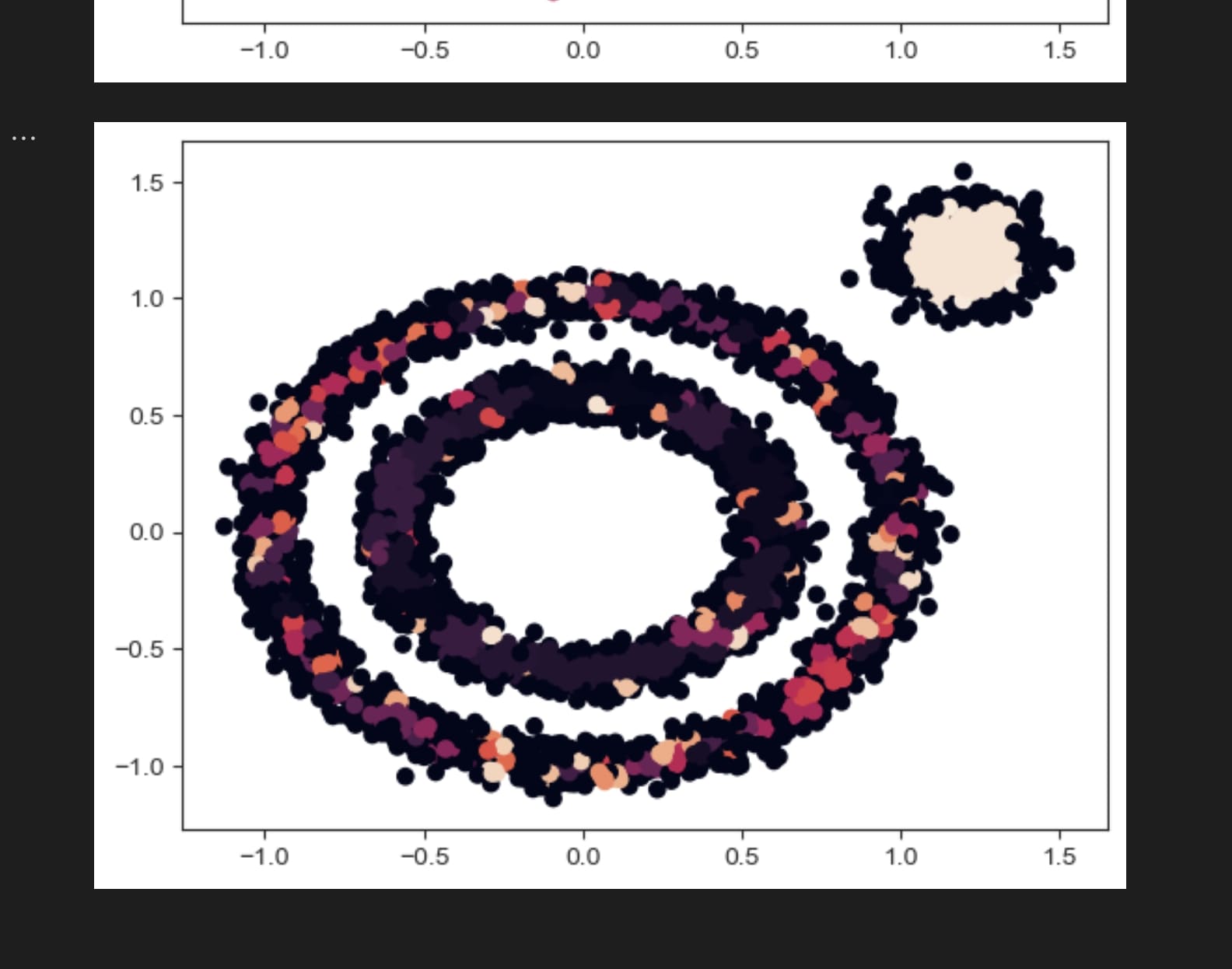
通过调整eps,可以人为决定聚类间的距离,从而实现将两个同心圆分成不同的聚类,十分强大。在lab的例子中,两个环状点集的大致距离是0.05左右,所以设置eps=0.05时算法表现出了很好的性能
另外,dbscan自带噪音过滤,图中的黑点即未被聚类的噪音。
eps=0.05
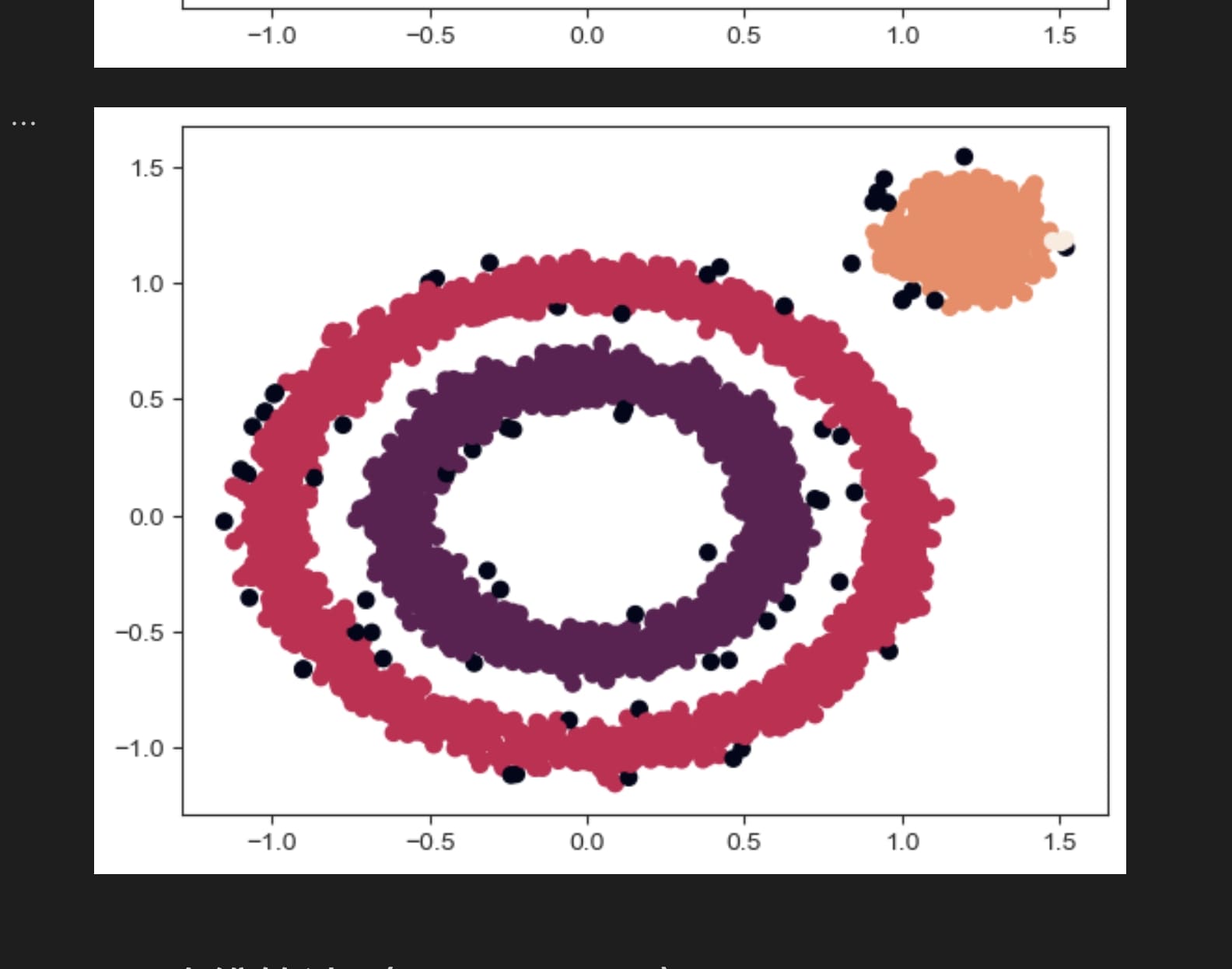
eps=0.02
降维-PCA
导包
from sklearn.decomposition import PCA
调用
pca = PCA(
n_components=2,
copy=True,
svd_solver='auto'
)
- n_components:维度
- 希望压缩到的维度,2或3用于可视化
- copy
- 是否复制数据集以避免重写
- svd_solver
- 希望采取的svd分解算法,auto即可
拟合与输出
return pca.fit_transform(data)
pca.fit_transform()返回降维后的数组(fortran-style),可以直接用来画图。
如果使用pca.fit(),会返回实例本身,处理麻烦。
可视化
plt.plot(reduced_data[:, 0], reduced_data[:, 1], "g.", markersize=2)
plt.xticks(())
plt.yticks(())
plt.show()
调参
pca的参数几乎没有操作空间,也不带分类效果(即在高维中相近的点在低维中也尽量相近)。尽管如此,它明显比tsne快非常多,所以有其存在价值。
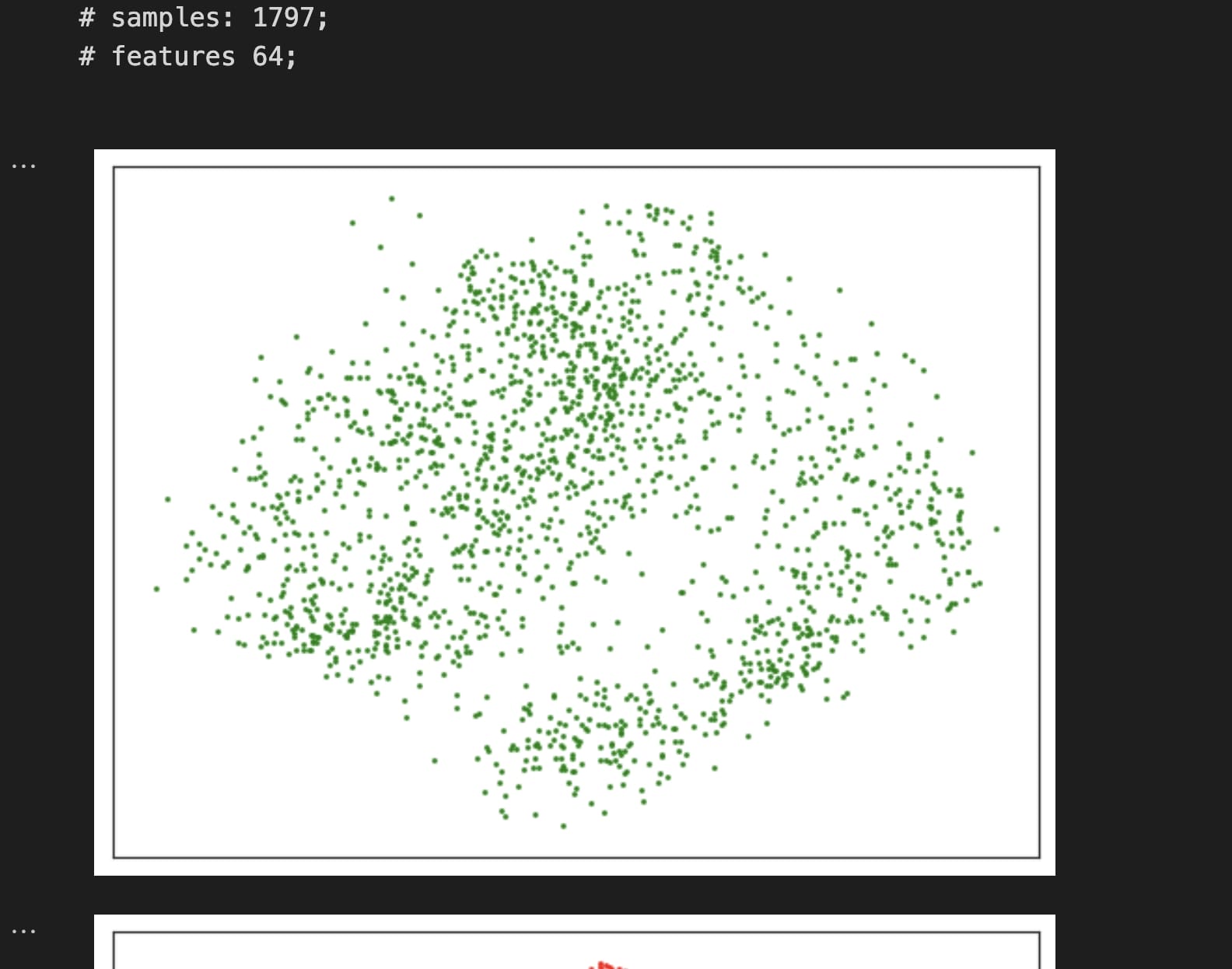
降维-tSNE
导包
from sklearn.manifold import TSNE
调用
tsne = TSNE(
n_components=2, # 希望压缩到的维度
perplexity=42, # 数据集小5~30,数据集大30~50
random_state=27 # 设置生成地图的种子
)
- n_components:维度
- 希望压缩到的维度,2或3用于可视化
- perplexity:神奇数
- 每个点的邻居数量估计,越大越考虑全局
- 小数据集5~30,大数据集30~50,大小大致以1000为界
- random_state:种子
- 生成地图的种子
拟合与输出
return tsne.fit_transform(data)
和pca类似,用.fit_transform()更方便。
可视化
plt.scatter(
reduced_data[:, 0], reduced_data[:, 1],
c=labels, cmap='tab10', s=10
)
plt.title("t-SNE colored")
plt.colorbar()
plt.xticks(())
plt.yticks(())
plt.show()
由于t-SNE自带分类的效果,所以采用彩色更合适。
调参
t-SNE相比PCA,有两个可调节的参数。perplexity是一个“魔数”,大概类似于DBScan中的eps,决定聚类的效果。random_state是生成种子,会让图象小幅度变化。
perplexity=40, random_state=20
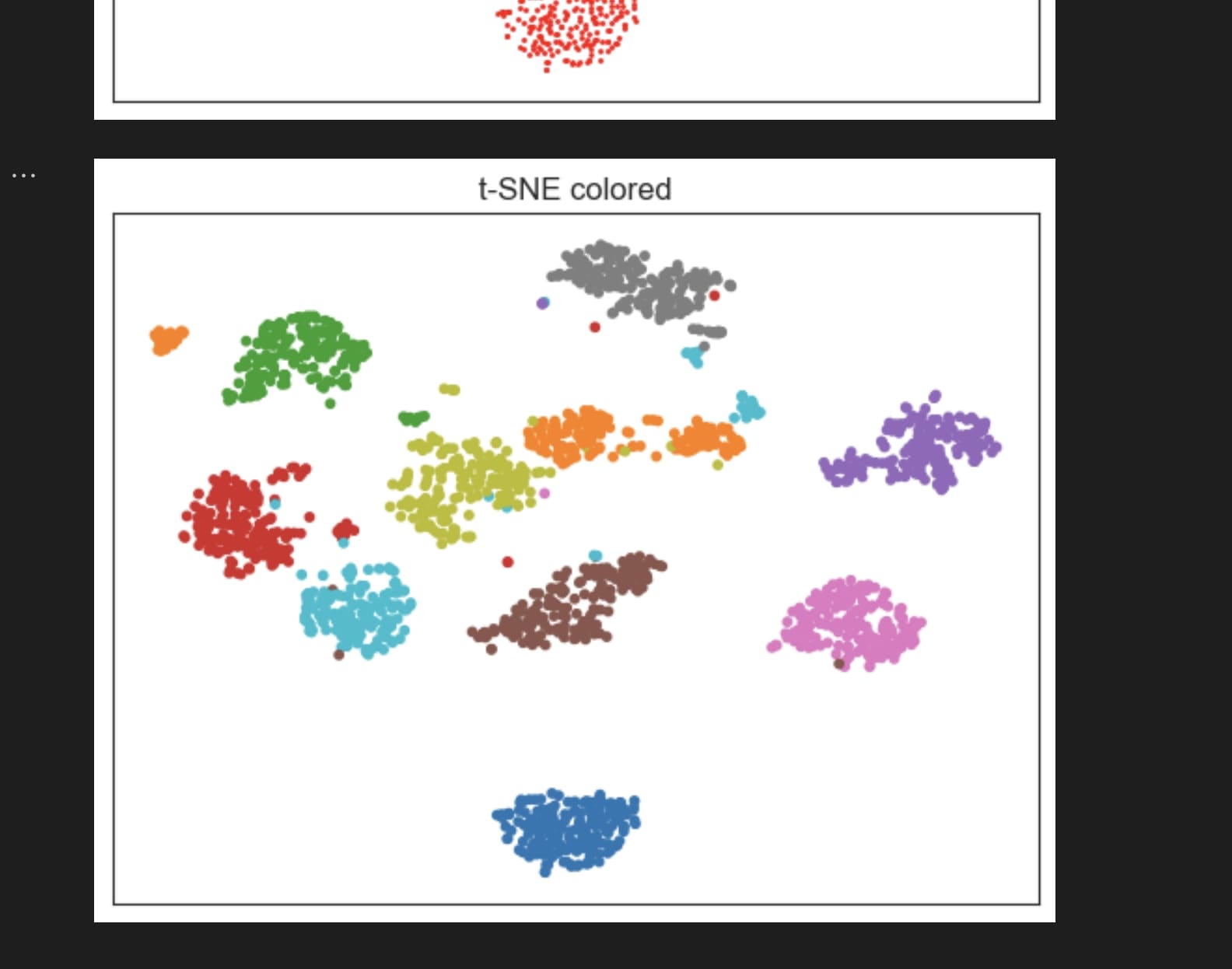
perplexity=20, random_state=40

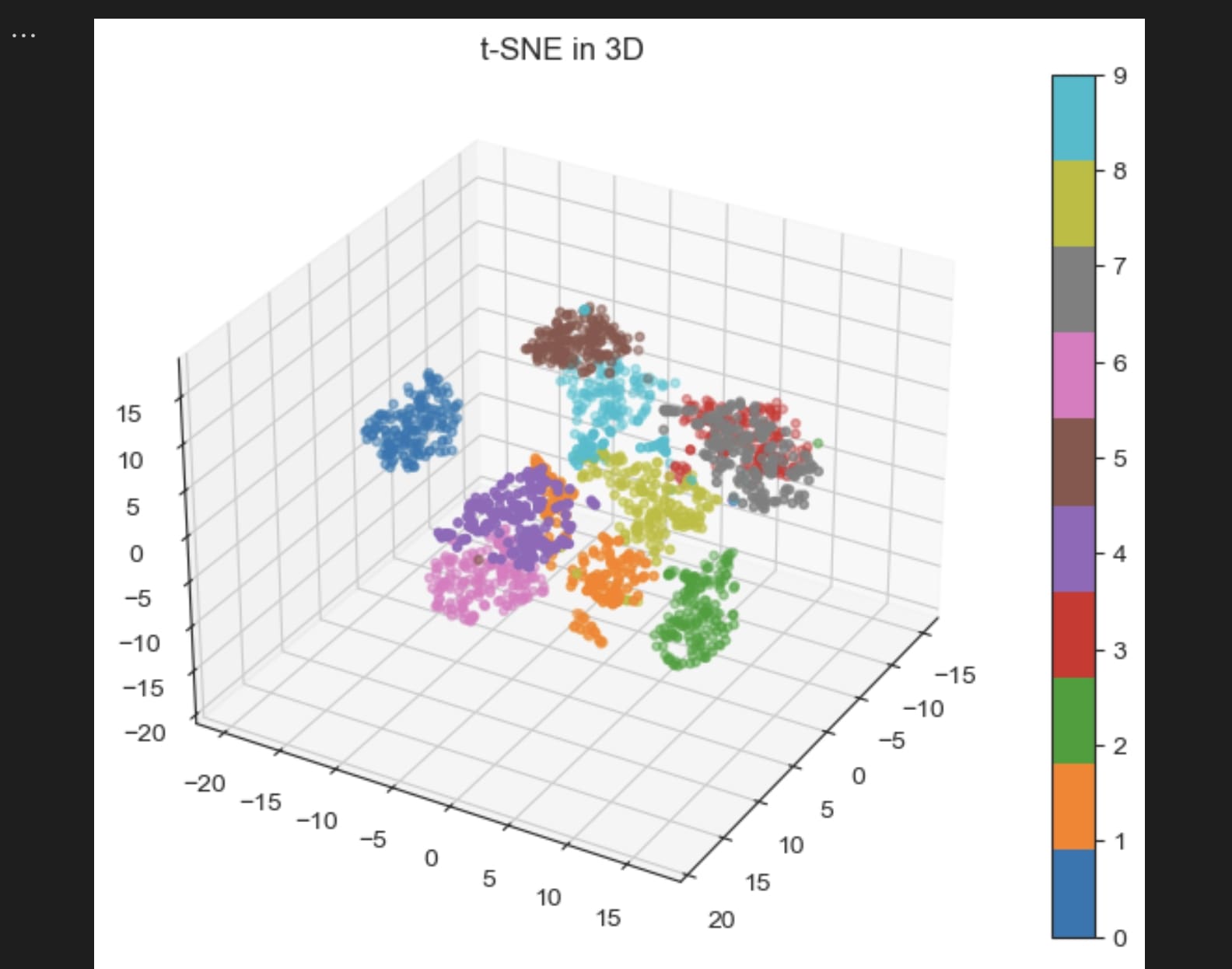
3D
还可以降维到3维空间中。
# 3D t-SNE
tsne = TSNE(n_components=3, perplexity=30, random_state=42, init='pca')
reduced_data = tsne.fit_transform(data)
# 可视化
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(
reduced_data[:, 0], reduced_data[:, 1], reduced_data[:, 2],
c=labels, cmap='tab10', s=10
)
ax.set_title("t-SNE in 3D")
ax.view_init(elev=30, azim=30)
plt.colorbar(scatter)
plt.show()
效果