lab5 cnn
lab5 深度学习入门:LeNet5和模型迁移
-
task1 在CIFAR-10上实现LeNet-5模型
- 数据集、训练、优化器
-
task2 迁移预训练深度卷积模型到CIFAR10
- resnet、冻结参数、微调
task1 在CIFAR-10上实现LeNet-5模型
目标
- 掌握图像分类任务和LeNet-5模型的基本构成
- 掌握卷积神经网络模型LeNet-5的前向计算和反向更新过程
- 掌握损失函数、随机梯度下降等概念
- 准确率目标:65%
实验内容
- 在CIFAR-10数据集上实现LeNet-5模型训练和测试全流程
- 在实验环境中训练LeNet-5模型,存储最终获得的模型参数
- 加载模型参数和测试集,计算模型的平均分类准确度
- 包:torchvision.datasets,torch.utils.data.DataLoader,torch.nn,torch.optim
LeNet5模型
结构
LeNet5有两层卷积层,两层池化层,三层全连接层。需要注意要让各层间的大小对齐。
激活函数的选择
我一开始选择了默认的tanh(),效果十分差,于是改成了relu。
数据集的加载与整理
通过torch.datasets可以很方便地自动下载数据集。数据集分为训练集和测试集,通过参数train来指定。另外,为了让数据集和模型输入对齐,还需要对数据集做变换,如正则化等,这通过参数transform来指定。
训练
轮数和学习率
这两个参数最重要,高轮数低学习率会很准确,但是时间长。
使用gpu
为了使用gpu进行加速,需要声明,否则将用cpu训练。对于苹果芯片,需要使用mps来进行加速。
device = torch.device(torch.device("mps" if torch.backends.mps.is_available() else "cpu"))
if torch.backends.mps.is_available():
print("mps on")
else:
print("mps off")
优化器的选择
都说Adam比SGD好,但是我还是用SGD了,因为发现低轮数下Adam似乎还不如SGD,而且二者的最佳学习率似乎不同。
动态学习率
随着轮数的增加,收敛速度越来越慢,此时可以用scheduler动态调整学习率。
保存模型参数
有两种保存方式,一种是只保存词表,另一种把epoch等信息也保存。后者对继续训练的支持更好,不过会明显让保存的文件变大。
可视化
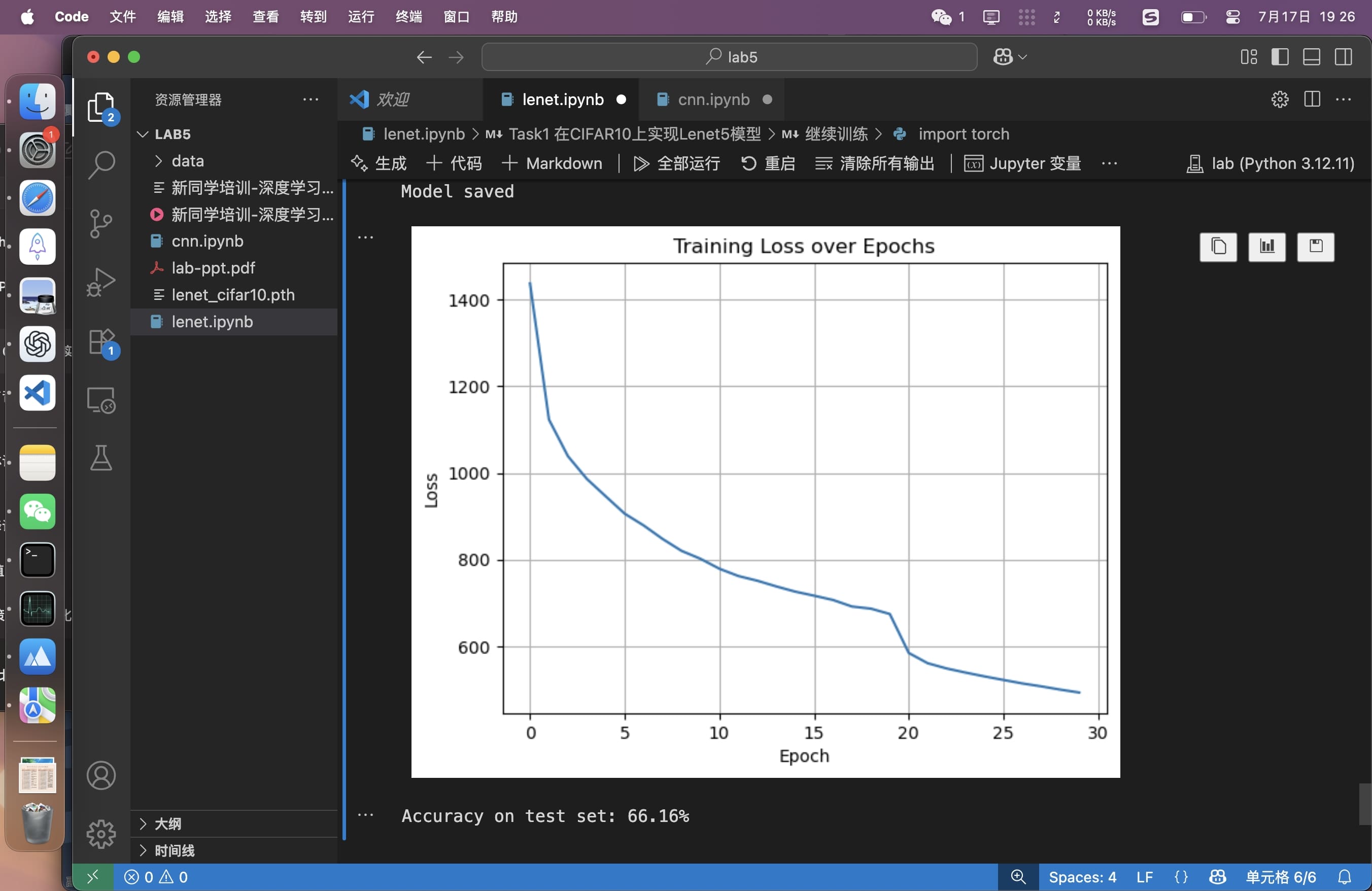
可以设置一个train_loss_list[],用来保存训练中每轮的损失,绘制成图表,可以很好地反映模型收敛的速度。另外对于加入scheduler的实现中,也可以把学习率绘制成图。
验证
流程
在保存模型参数后,加载模型,然后设置model.eval()锁定模型参数。然后加载测试集,计算正确分类的数量与全部的比值。
验证脚本
为了方便测试,可以单独写一个测试用的脚本,需要注意的是也需要给出模型结构的实现。也可以在训练脚本中轮数设为0。
实现
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
import torch.nn.functional as nnf
import matplotlib.pyplot as plt
import os
# flags
download = not os.path.exists('./data/cifar-10-batches-py')
optimzr = 'SGD'
rounds = 20
lr = 0.01
train_loss_list = []
# 数据集
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = datasets.CIFAR10(
root='./data',
train=True,
download=download,
transform=transform
)
testset = datasets.CIFAR10(
root='./data',
train=False,
download=download,
transform=transform
)
trainloader = DataLoader(
trainset,
batch_size=64,
shuffle=True
)
testloader = DataLoader(
testset,
batch_size=64,
shuffle=False
)
# 模型定义
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(
3, # 输入频道
6, # 输出频道
kernel_size=5 # 核函数大小
)
self.pool = nn.AvgPool2d(
kernel_size=2,
stride=2
)
self.conv2 = nn.Conv2d(
6,
16,
kernel_size=5
)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# conv-pool 1
x = self.pool(nnf.relu(self.conv1(x)))
# conv-pool 2
x = self.pool(nnf.relu(self.conv2(x)))
# fc
x = x.view(-1, 16 * 5 * 5)
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
x = self.fc3(x)
return x
# 加载设备
device = torch.device(torch.device("mps" if torch.backends.mps.is_available() else "cpu"))
model = LeNet5().to(device)
if torch.backends.mps.is_available():
print("mps on")
else:
print("mps off")
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
if optimzr == 'SGD':
optimizer = optim.SGD( # 随机梯度下降
model.parameters(),
lr=lr, # 学习率
momentum=0.9 # 动量
)
elif optimzr == 'Adam':
optimizer = torch.optim.Adam(
model.parameters(),
lr=lr
)
else:
print("optimizer not selected")
exit()
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer,
step_size=10,
gamma=0.5
)
# 训练
for epoch in range(rounds):
running_loss = 0.0
for i, (inputs, labels) in enumerate(trainloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss:.3f}")
train_loss_list.append(running_loss)
# 保存模型参数
torch.save(model.state_dict(), 'lenet_cifar10.pth')
print("model saved")
# 加载模型并测试
model = LeNet5().to(device)
model.load_state_dict(torch.load('lenet_cifar10.pth'))
print("model loaded")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on test set: {100 * correct / total:.2f}%")
# 可视化训练误差
plt.plot(train_loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss over Epochs")
plt.grid(True)
plt.show()
效果
训练10轮,不足以达到要求,而且收敛越来越慢
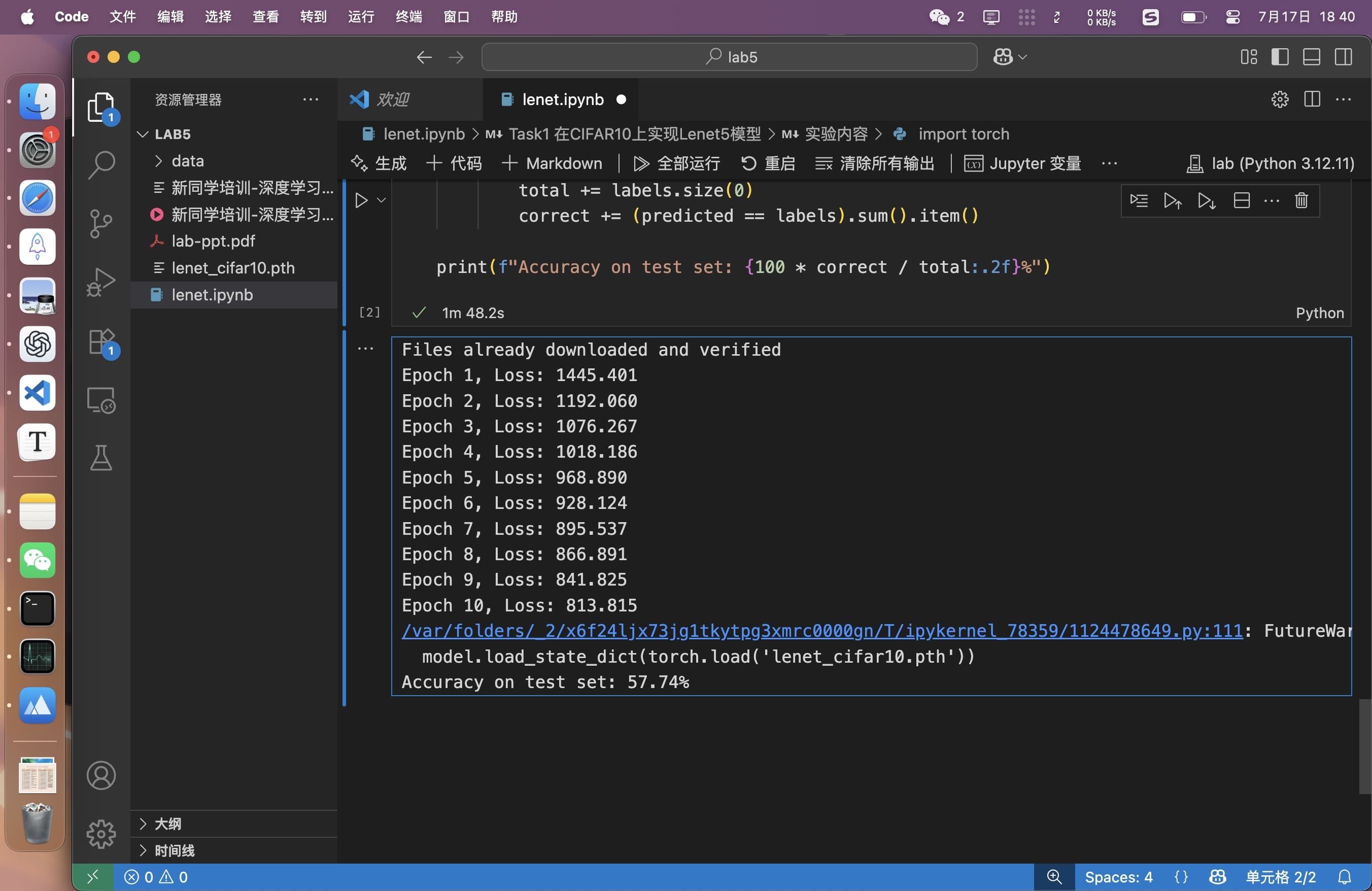
又增加了5轮并且使用了scheduler,达到目标。但是不知道为什么loss在继续训练的第一个epoch发生了跳变。
task2 迁移预训练深度卷积模型到CIFAR10
目标
- 掌握模型迁移学习概念
- 掌握模型迁移学习的基本方法
- 准确率目标:90%
实验内容
- 从torchvision上下载预训练的深度卷积神经网络,如ResNet、VGG等 • 调整网络结构,使其适配CIFAR-10数据集分类任务
- 冻结特征提取部分,训练分类头
- 加载测试集,计算迁移后模型的平均分类准确度
原理
迁移学习(Transfer Learning) 是一种将一个任务上学到的知识迁移到另一个相关任务的学习方法。尤其适用于训练数据量较小的任务。核心思想是:
在源任务(如ImageNet分类)中训练好的模型具有较强的特征提取能力,可以迁移到目标任务(如CIFAR-10分类)中进行再利用。
例子:
- 在ImageNet上训练好的ResNet已经学会了提取边缘、纹理、形状等视觉特征;
- 在CIFAR-10任务中,我们可以复用ResNet的前几层(作为特征提取器),只重新训练最后几层(分类器),以快速适配新任务。
迁移
对齐数据集和模型
因为预训练的resnet是基于imagenet数据集的,有1000个label,所以需要先把最后一层替换成适合cifar10的nn.Linear(num_features, 10)。另外,输入的cifar10也需要转换成imagenet的形状,使用transforms.Resize(224)实现,另外还需要正则化到imagenet的均值方差。
冻结参数
实现模型迁移的重点就在于冻结部分参数,只训练后面的层。先冻结所有参数,再解冻fc层。所谓冻结/解冻就是设置bool param.requires_grad。
微调
如果只训练后面的fc层(分类头),而把其他参数全部冻结,分类准确度可能不能达标。所谓微调,就是在迁移过程中其他层的参数也参与训练。对于resnet18,可以把它的layer4也一起训练。
在优化器的设置中,可以把layer4的学习率调得比fc低一些。
Adam的自适应学习率调整和Scheduler并不冲突,Scheduler根据轮数修改base_lr,而Adam再次基础上根据每个参数的梯度调整微观的学习率。不过我觉得Scheduler对训练速度的提升效果并不明显。
实现
实现是基于微调的,因为如果不动layer4会导致收敛不到90%。
import torch
from torchvision import models
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, models
from torchvision.transforms import InterpolationMode # 插值用,提高加载速度
from tqdm import tqdm # 进度条
import matplotlib.pyplot as plt
import os
# flags
rounds=5
os.environ['TORCH_HOME'] = os.path.expanduser('~/lab5/model')
download=False
resume=False
schedule=True
lr_fc=0.001
lr_l4=0.0001
train_loss_list = []
lr_list = []
# 加载cifar10
transform_train = transforms.Compose([
transforms.Resize(224, interpolation=InterpolationMode.BILINEAR), # ImageNet输入大小
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
transform_test = transforms.Compose([
transforms.Resize(224, interpolation=InterpolationMode.BILINEAR),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=2)
# 加载设备
device = torch.device(torch.device("mps" if torch.backends.mps.is_available() else "cpu"))
if torch.backends.mps.is_available():
print("mps on")
else:
print("mps off")
# 加载模型
if download:
model = models.resnet18(pretrained=True)
else:
if resume:
model = models.resnet18()
model.fc = nn.Linear(model.fc.in_features, 10) # 需要重建模型
model.load_state_dict(torch.load('/Users/anpoliros/lab5/model/resnet18-tunned.pth'))
else:
model = models.resnet18()
model.load_state_dict(torch.load('/Users/anpoliros/lab5/model/resnet18-f37072fd.pth'))
model.fc = nn.Linear(model.fc.in_features, 10) # 需要重建模型
for param in model.parameters(): # 冻结参数
param.requires_grad = False
for param in model.fc.parameters(): # 调整fc层
param.requires_grad = True
for param in model.layer4.parameters(): # 调整layer4层
param.requires_grad = True
model = model.to(device)
print("model loaded")
# 优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam([
{'params': model.layer4.parameters(), 'lr': lr_fc},
{'params': model.fc.parameters(), 'lr': lr_l4}
])
if schedule:
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer,
step_size=10,
gamma=0.5
)
# 训练
for epoch in range(rounds) :
model.train()
running_loss = 0.0
correct, total = 0, 0
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}"):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item() # 统计准确率
if schedule: scheduler.step()
acc = correct / total * 100
print(f"Epoch {epoch+1}/{rounds}, Loss: {running_loss:.4f}, Train Accuracy: {acc:.2f}%")
print("\n")
avg_loss = running_loss / len(train_loader)
train_loss_list.append(avg_loss)
lr_list.append(optimizer.param_groups[0]["lr"])
print(f"avg_Loss: {avg_loss:.4f}, LR: {lr_list[-1]:.6f}")
# 保存模型参数
torch.save(model.state_dict(), 'resnet18-tunned.pth')
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}, 'resnet18-checkpoint.pth')
print("model saved")
# 测试
model.eval()
correct, total = 0, 0
with torch.no_grad():
for images, labels in tqdm(test_loader, desc="Test"):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_acc = correct / total * 100
print(f"Test Accuracy: {test_acc:.2f}%")
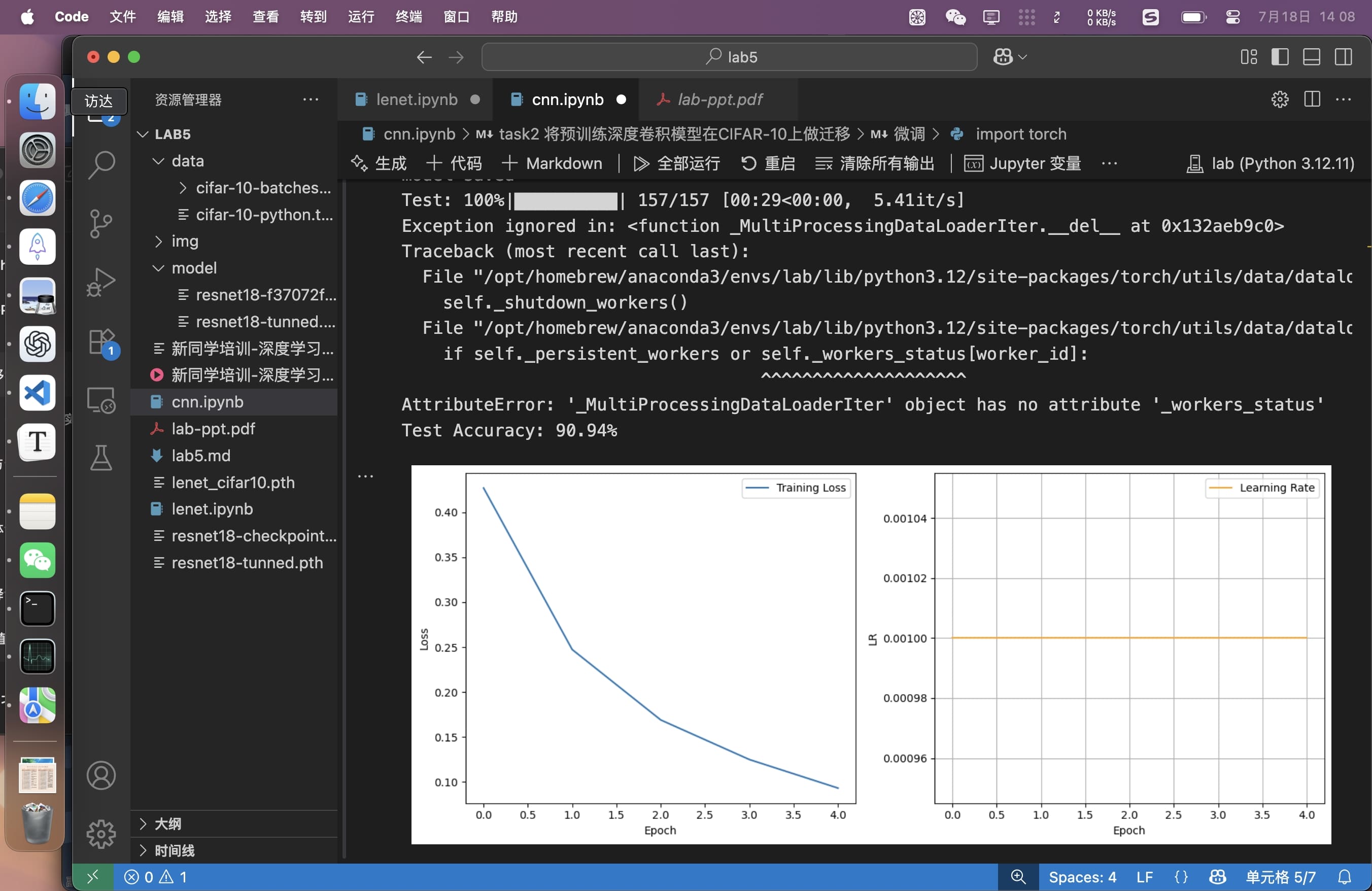
# 可视化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1) # 损失曲线
plt.plot(train_loss_list, label='Training Loss')
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.subplot(1, 2, 2) # 学习率曲线
plt.plot(lr_list, label='Learning Rate', color='orange')
plt.xlabel("Epoch")
plt.ylabel("LR")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
效果
仅调整fc层,训练5轮,达不到目标。
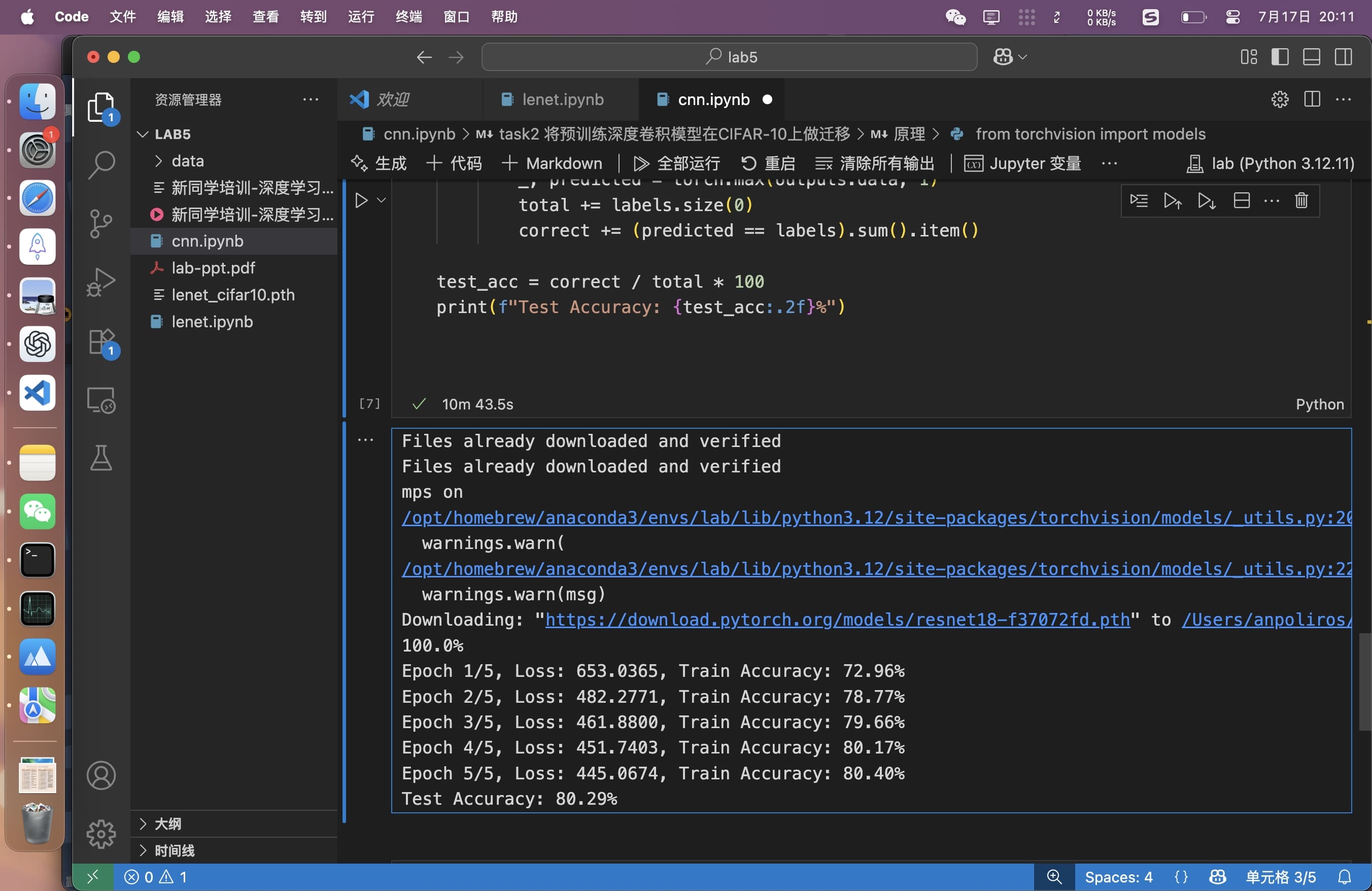
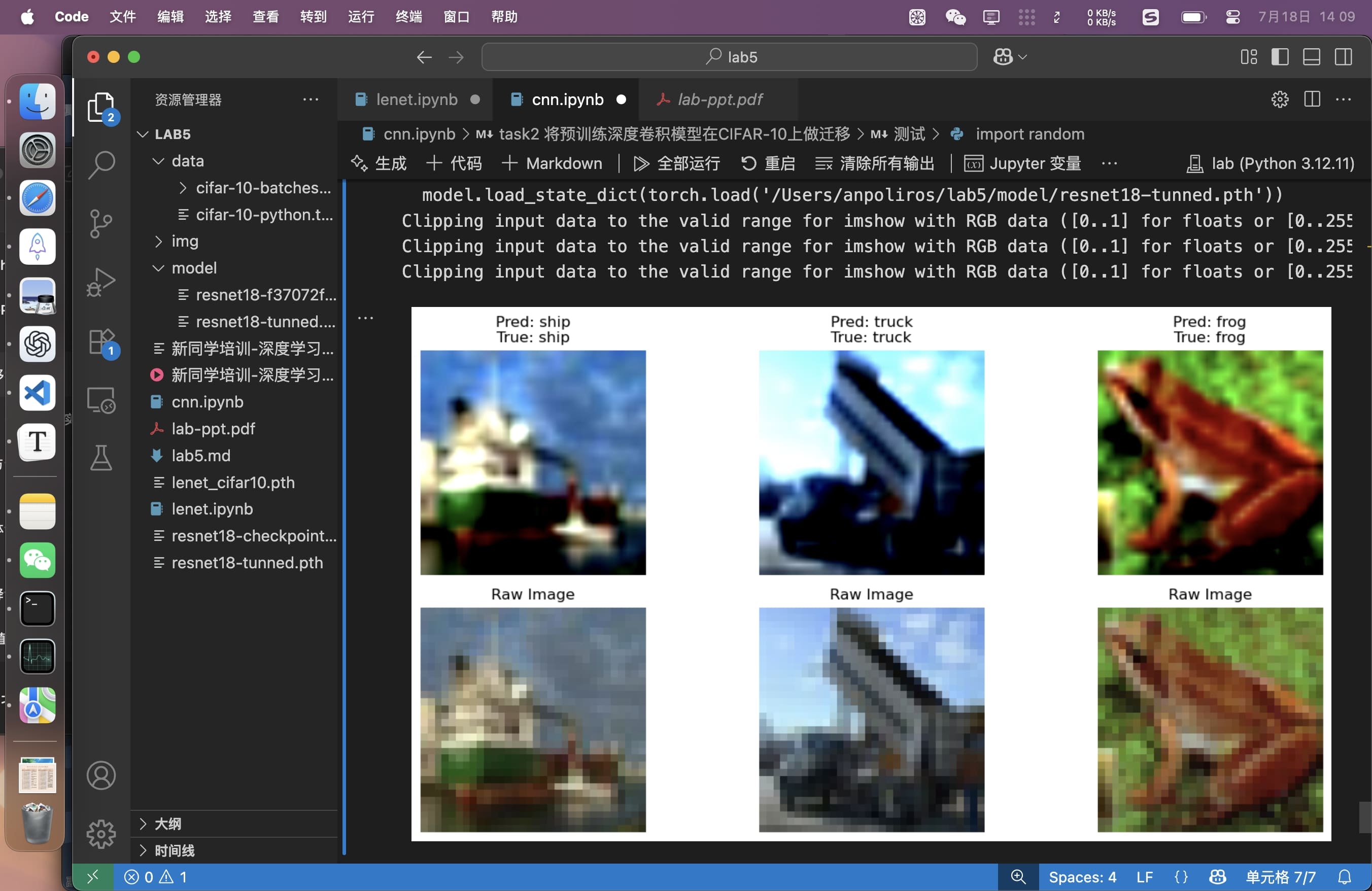
微调layer4,训练5轮即达到目标。
可视化loss和lr。
可视化数据集和模型分类的过程。