lab6 chat
lab6 使用商用大模型
-
Task #0: chat脚本
-
Task #1: 上下文学习(In-Context Learning)
- 能力评测
-
Task #2: 文本Embedding
- modelscope、热力图
-
Task #3: 知识库
-
Task #4: RAG
- langchain、faiss
-
Task #5: Tools
- flask api
Task #0: 用脚本请求商用大模型
目标
- 学会使用python脚本请求商用大模型
实验内容
- 注册并选择硅基流动上的任意大语言模型作为你的实验对象 ,获取免费额度
- 阅读文档,撰写Python脚本,实现对大模型的自动化请求
- 包装成一个名为chat的函数,便于后面使用
实现
shell
查看api文档,选择创建对话请求(OpenAI)。给出的curl是
curl --request POST \
--url https://api.siliconflow.cn/v1/chat/completions \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '{
"model": "Qwen/QwQ-32B",
"messages": [
{
"role": "user",
"content": "What opportunities and challenges will the Chinese large model industry face in 2025?"
}
]
}'
替换<token>为自己的token,在终端中执行,就可以得到回复了。
python
可以使用requests库用python实现curl的效果,有点像python爬虫,流程大同小异。
封装函数chat(prompt),其中prompt为提示词即问题。需要注意的是服务器返回的是json,如果要仅打印出回复内容,需要做格式化处理。
参数
model
千万别选推理模型,根本无法完成50道题的要求,太慢了。我最后选的Qwen/Qwen2.5-7B-Instruct。实测关闭enable_thinking并没有什么用,json dump出来还是reasoning了。
proxy
可以在chat()中使用proxies,但是不知道为什么还总是走代理,全局规则、函数内代理、调用时代理都试了,全都没用哈哈哈。最后只能关掉系统代理跑。
import requests
import json
from datetime import datetime
# flags
API_KEY = "sk-gizecqazixxccvnlezkwktuwfxqexfznxnacgxuabduxkxnj"
ENDPOINT_URL = "https://api.siliconflow.cn/v1/chat/completions"
VERBOSE = True
MODEL = "Qwen/Qwen2.5-7B-Instruct"
# chat
def chat(prompt, model=MODEL, save_path="history.txt", verbose=False):
"""
prompt: prompt
model: 选择模型
save_path: 历史记录路径
verbose: 保存完整json
"""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
data = {
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0.7
}
# 发送请求
response = requests.post(ENDPOINT_URL, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
if verbose: # save json
print(f"model: {model}\n")
resp = requests.get("https://ipinfo.io")
print(f"proxies: {resp.json()}\n")
with open("response.json", "w", encoding="utf-8") as file:
json.dumps(data, indent=2)
json.dump(result, file, ensure_ascii=False, indent=2)
print("json saved")
reply = result['choices'][0]['message']['content'].strip() # parsing
with open(save_path, "a", encoding="utf-8") as f: # save history
f.write(f"[{datetime.now()}] User: {prompt}\n")
f.write(f"[{datetime.now()}] Assistant: {reply}\n\n")
return reply
else:
print("Failed:", response.status_code, response.text)
return None
Task #1: 大模型能力评测和上下文学习(In-Context Learning)
目标
- 理解大模型能力测评的全流程
- 理解0-shot和few-shot的概念
- 学会In-Context Learning
实验内容
- 学习大模型能力选择题Benchmark C-Eval
- 选择50个测试问题,对0x0中的大模型进行评测,对比0—shot和5—shot的结果
准备
C-Eval能力测评
- C-Eval 是一个针对中文场景下的大语言模型评估数据集
- 它包含了 52 个学科方向、超过1.4万道选择题,类似高考、考研、公务员题
- 每道题是 4 选 1
shot的概念
- 0-shot: 模型直接看到题目就答,没有示例题
- n-shot: 在题目前提供n个参考示例题和答案,帮助模型学习“如何回答”
In-Context Learning
上下文语境学习: 通过在上下文中提供一些信息,让模型即时学习,提高表现水平,而无需改变任何参数。
流程
准备题目数据
c-eval的github page上提供了各种调用方法,这里选择使用datasets。第一次启动会把题目数据集cache到本地。加载后,还需要格式化一下以供构造prompt用。
设计prompt
要求大模型只回答一个字母是很有必要的。
评测脚本
必须一次一个问题地测试,否则上下文就被破坏了。这更要求我们使用低端的大模型,千万不要用reasoning模型。
效果
我尝试了计算机网络和高中物理两个数据集,都发现5-shot和0-shot基本没有区别,如果q_num设置的小一点,更离谱的是5-shot的正确率甚至显著下降。
我觉得这是因为试题之间并不能提供举一反三的效果,如果想显著测试5-shot,应该专门设计试题,就像小学一课一练那种感觉。
import json
import random
import requests
from datetime import datetime
import re
from datasets import load_dataset # 加载c-eval
from lib.chat import chat # 导入封装的chat
resp = requests.get("https://ipinfo.io", proxies=None)
print(resp.json())
# flags
Q_NUM = 30
def load_questions(subject="middle_school_physics", n=Q_NUM, split="val"):
"""
- subject: 所选学科名称,如 'computer_network'
- n: 返回的问题数量
- split: 使用 'val' 或 'test' 集合
return
- 格式统一的题目列表
"""
ds = load_dataset(r"ceval/ceval-exam", name=subject)
print("dataset loaded")
all_qs = list(ds[split])
selected = random.sample(all_qs, min(n, len(all_qs)))
formatted = []
for q in selected:
formatted.append({
"question": q["question"],
"options": [f"A. {q['A']}", f"B. {q['B']}", f"C. {q['C']}", f"D. {q['D']}"],
"answer": q["answer"]
})
return formatted
def build_prompt(target_q, shots=0, examples=None):
prompt = f"以下是单项选择题,前{shots}个题是例子,请直接给出最后一题正确选项的字母。\n\n"
# few-shot
if shots > 0 and examples:
for ex in examples[:shots]:
prompt += f"示例题目:{ex['question']} "
for opt in ex['options']:
prompt += opt + " "
prompt += f"答案:{ex['answer']} \n"
# 添加目标题
prompt += f"目标题目:{target_q['question']} \n"
for opt in target_q['options']:
prompt += opt + "\n"
prompt += "答案:?"
return prompt
def extract_choice(text):
match = re.search(r"[A-D]", text.upper())
return match.group(0) if match else ""
def evaluate(questions, shots=0):
correct = 0
for i, q in enumerate(questions):
examples = random.sample([x for x in questions if x != q], k=shots) if shots > 0 else []
prompt = build_prompt(q, shots, examples)
reply = chat(prompt)
predicted = extract_choice(reply)
print(f"[Q{i+1}] 预测:{predicted} | 正确:{q['answer']}")
if predicted == q['answer']:
correct += 1
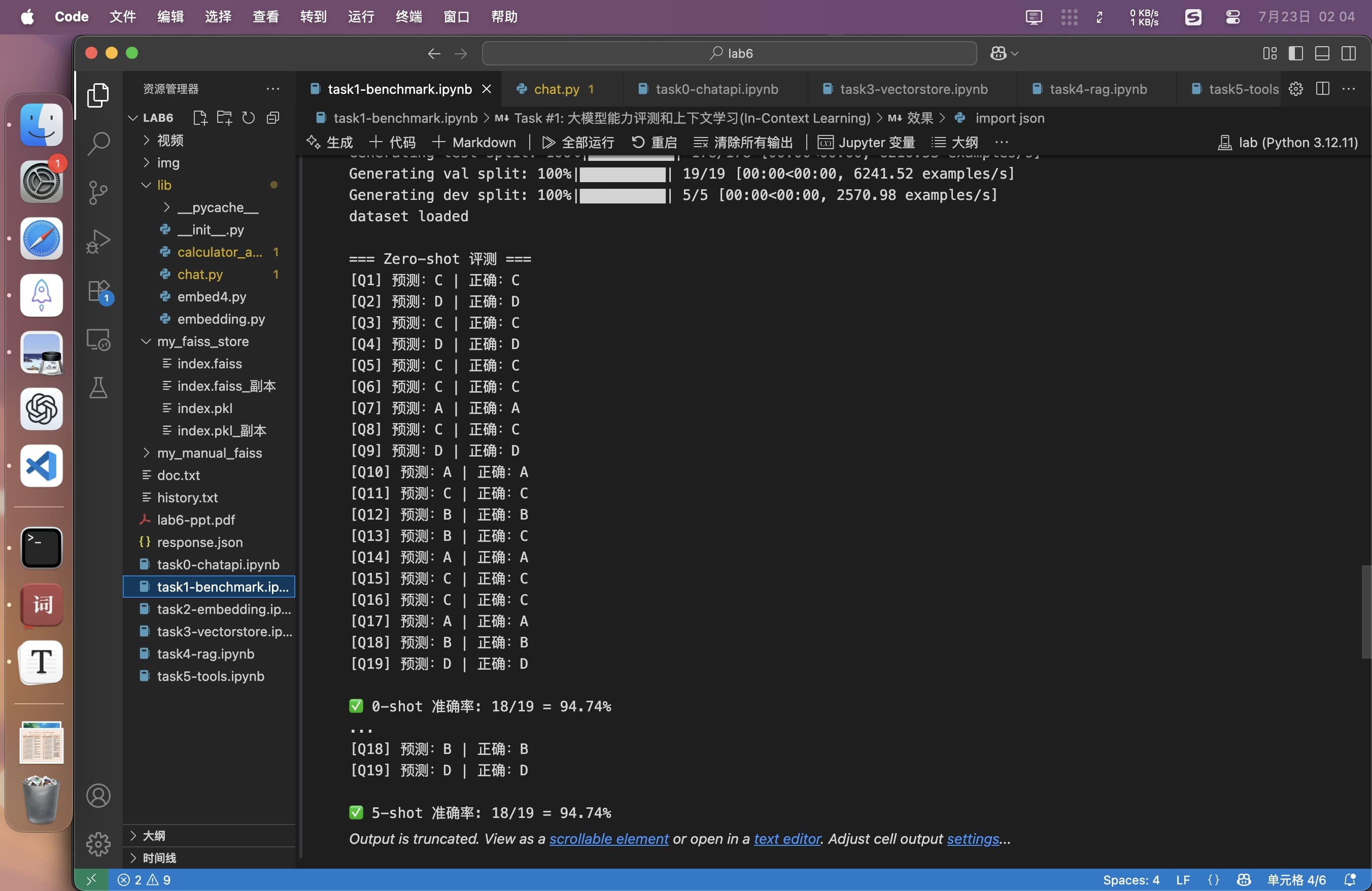
acc = correct / len(questions)
print(f"\n {shots}-shot 准确率: {correct}/{len(questions)} = {acc:.2%}")
return acc
if __name__ == "__main__":
qs = load_questions()
print("\n=== Zero-shot 评测 ===")
evaluate(qs, shots=0)
print("\n=== 5-shot 评测 ===")
evaluate(qs, shots=5)
Task #2: 学会使用文本Embedding
目标
- 理解文本embedding模型的结构
- 部署和使用embedding model
实验内容
-
学习基于language model的文本embedding
-
参考BERT模型原文 https://arxiv.org/abs/1810.04805
-
参考SentBERT https://arxiv.org/abs/1908.10084
-
尝试在自己的电脑上或者modelscope平台的云服务器上部署一个embedding模型(无需GPU)
-
GTE文本向量-英文-通用领域-small link
-
GTE文本向量-中文-通用领域-small link
-
思考并尝试:Embedding模型有什么用?自己设计一个Case
文本embedding模型
文本嵌入(Text Embedding),就是把文本映射到实数向量。直观地讲,就是把单词嵌入到一个n维空间中。这些向量能够捕捉文本之间的语义关系,让计算机可以理解文字的含义,从而应用在各种NLP任务中。
传统方法的缺点:
- One-Hot: 使用标准正交基$e_i$,类似flag,维度高开销大
- TF-IDF: 基于出现频率按权重编码,类似huffman,不可解释
embedding的优点:
- 压缩维度,占用小
- 相似意思的单词,在空间中距离近
- 满足可加性,红+苹果=红苹果
环境地狱
我没想到modelscope的环境如此难配。上来不能conda install也许就初现端倪,然后就是不停地需要各种小依赖,还不能一键装完。
一切就绪了后,报错torch版本高于2.6.0。升级了torch之后一切都混乱了。找不到transformer。torchvision冲突。麻了,让我们专门重新特别给这个task2创建个conda环境好吧。
conda create -n gte-clean python=3.9 -y
conda activate gte-clean
# 安装核心库
pip install torch==2.6.0 transformers sentencepiece modelscope accelerate
pip install simplejson addict sortedcontainers termcolor PIL
验证
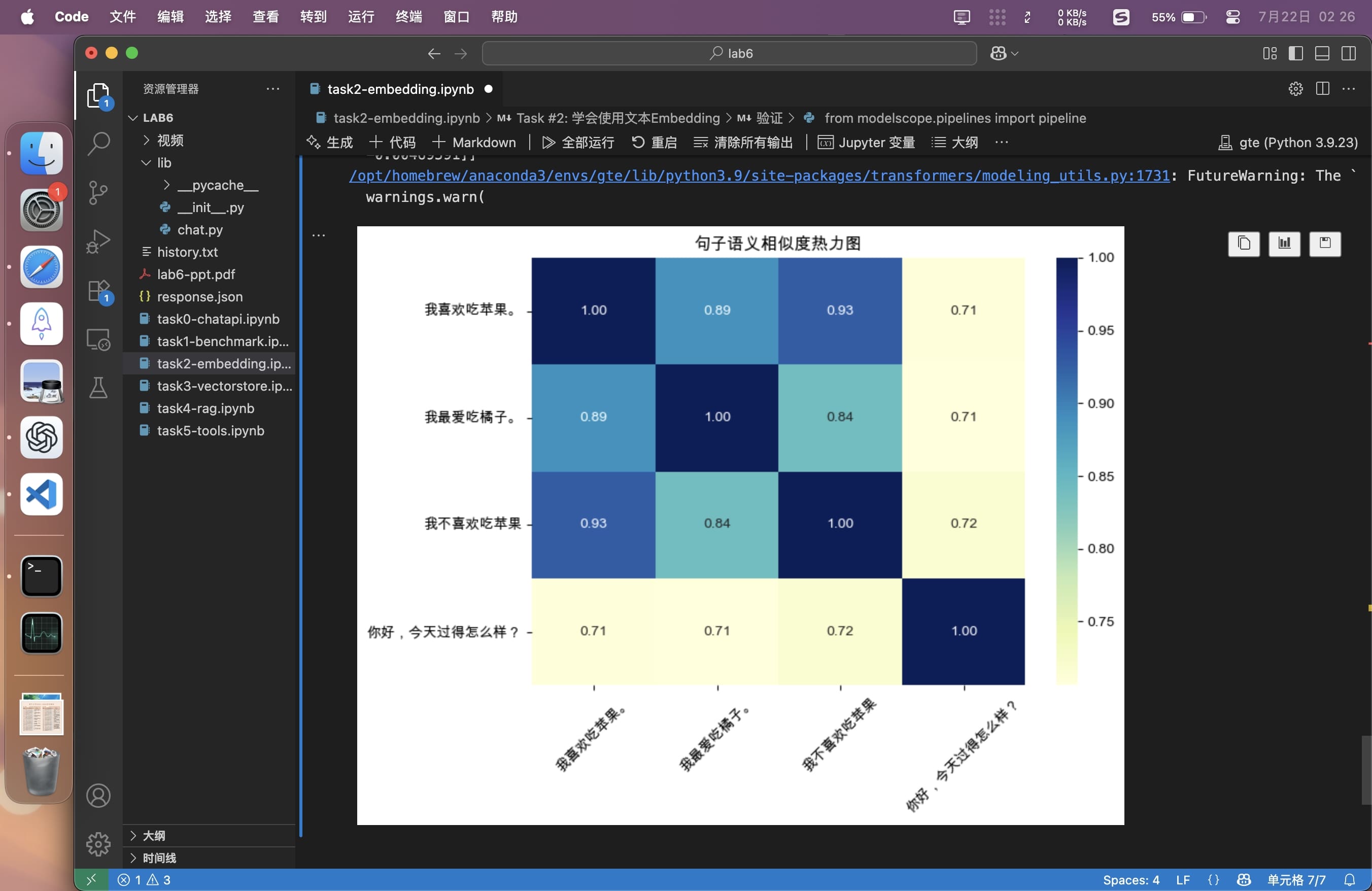
为了验证“意思相近距离相近”,使用余弦相似度计算,并且用热力图可视化。
可以看到相似的句子确实距离更近。需要注意的是,由于使用的这个模型是句子级别的嵌入,所以如果测试单词相关度就不会得到很好的结果。
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
import matplotlib.pyplot as plt
# 中文标签
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
# 创建 embedding pipeline
embedder = pipeline(
task=Tasks.sentence_embedding,
model='iic/nlp_gte_sentence-embedding_chinese-small'
)
sentences = [
'我喜欢吃苹果。',
'我最爱吃橘子。',
'我不喜欢吃苹果。',
'你好,今天过得怎么样?'
]
result = embedder({
'source_sentence': sentences
})
embs = result['text_embedding']
sim_matrix = cosine_similarity(embs) # 余弦相似度
print(np.round(sim_matrix, 2))
print(embs)
# 可视化
plt.figure(figsize=(8, 6))
sns.heatmap(sim_matrix, annot=True, fmt=".2f", xticklabels=sentences, yticklabels=sentences, cmap='YlGnBu')
plt.title("句子语义相似度热力图")
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()
Task #3: 知识库构建和向量索引
目标
- 学习构建向量知识库
实验内容
- 找一篇你感兴趣的文章
- 学习Langchain中TextSplitter的概念,将文章分成chunks
- 使用#2中构建的Embedding模型,将chunks转换为embedding
- 学习FAISS向量数据库的概念和使用方法
- 基于这篇文章构建并保存一个VectorStore,并能够读取
参考文档
- https://python.langchain.com/docs/tutorials/rag/
准备知识
向量知识库(Vector Knowledge Base)
向量知识库是一种基于 Text Embedding 的知识存储与检索系统。将文本转换为向量后,可以用余弦相似度等方式进行语义相似度查询。适用于问答系统(RAG)、文档搜索、多轮对话记忆等,是RAG的重要准备工作。
LangChain
LangChain 是一个用于构建基于 LLM 应用的框架,它提供了许多组件来集成语言模型与外部数据源(如数据库、文档、API等)。
本实验中用到:
- TextSplitter:将长文本拆分为可向量化的短块(chunk)
- Embeddings:语言模型嵌入接口
- VectorStore:向量数据库的抽象接口
FAISS
FAISS(Facebook AI Similarity Search)是由 Meta 开发的高效向量相似度检索库,支持百万级数据规模、快速查询、多种索引结构,是当前最主流的向量数据库工具之一。
流程
- 选择一篇文章并拆分文本
- 加载中文嵌入模型
- 这里我将task2实现的embedding封装,便于调用
- 构建并保存向量数据库
- 加载并执行语义检索,返回最相关的片段
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.docstore.document import Document
from lib.embedding import ModelScopeEmbedding
# 文章文本
raw_text = """
LangChain 是一个用于开发由大型语言模型驱动的应用程序的框架。它让应用能够访问数据源、具有代理能力,能够与外部环境交互。LangChain 主要用于构建 RAG 系统、问答机器人、文档搜索引擎等场景。
"""
# 拆分文本为 chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=10,
separators=["\n", "。", ",", " "]
)
docs = text_splitter.create_documents([raw_text])
# 初始化嵌入器
embedding = ModelScopeEmbedding()
# 构建 FAISS 知识库
vectorstore = FAISS.from_documents(docs, embedding)
# 保存本地知识库
vectorstore.save_local("my_faiss_store")
# 加载保存的 VectorStore
new_vectorstore = FAISS.load_local(
"my_faiss_store",
embedding,
allow_dangerous_deserialization=True # 关闭安全加载,允许任意pickle
)
# 查询
query = "LangChain 是干什么用的?"
results = new_vectorstore.similarity_search_with_score(query, k=2)
# 打印结果
for doc, score in results:
print(f"[Score: {score:.4f}] {doc.page_content}")
Task #4: Retrieval-Augmented Generation 检索增强生成
目标
- 理解RAG的原理
- 手搓RAG
实验内容
- 自行搜集资料,学习RAG的机制
- 基于#0的实现的大模型接口,#1的上下文学习和#3的Vectorstore,做一个根据文章内容的QA应用 (注意:禁止使用Langchain,请自行实现RAG的流程)
准备知识
RAG
检索增强生成 Retrieval-Augmented Generation 就是让大模型回答时先看一眼文档,这样会让结果的可信度更高,有效避免幻觉的出现。实际上这正是上下文学习 In-Context Learning 和向量知识库 Vector Knowledge Base 的融合实现。
流程
- 用户提问(Query)
- 将 Query 向量化
- 使用 FAISS 检索 Top-k 相关文档块
- 将文档块拼接成 Prompt
- 调用大语言模型(如 OpenAI ChatGPT)生成回答
实现
我尝试了很多次,包括用task3中的embedding,重新实现embedder,在脚本内实现embedder,重新实现写入faiss store,在脚本内实现写入faiss store。当然,无一例外都失败了,从版本兼容性问题到文件写入问题,甚至莫名其妙的python内核崩溃。
我不得不使用langchain了。另外不用langchain一键实现就行吧,我觉得下面的实现还是很详细的。
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader # load
from langchain.schema import Document
from lib.chat import chat
# 加载doc
loader = TextLoader("doc.txt", encoding="utf-8")
raw_documents = loader.load()
# 切分文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
documents = text_splitter.split_documents(raw_documents)
# 构建embedding模型(huggingface)
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# 构建向量数据库
vectorstore = FAISS.from_documents(documents, embedding_model)
# vectorstore.save_local("faiss_index") # 持久化
# 查询doc
def retrieve_docs(query, top_k=3):
docs = vectorstore.similarity_search(query, k=top_k)
return docs
# rag流程
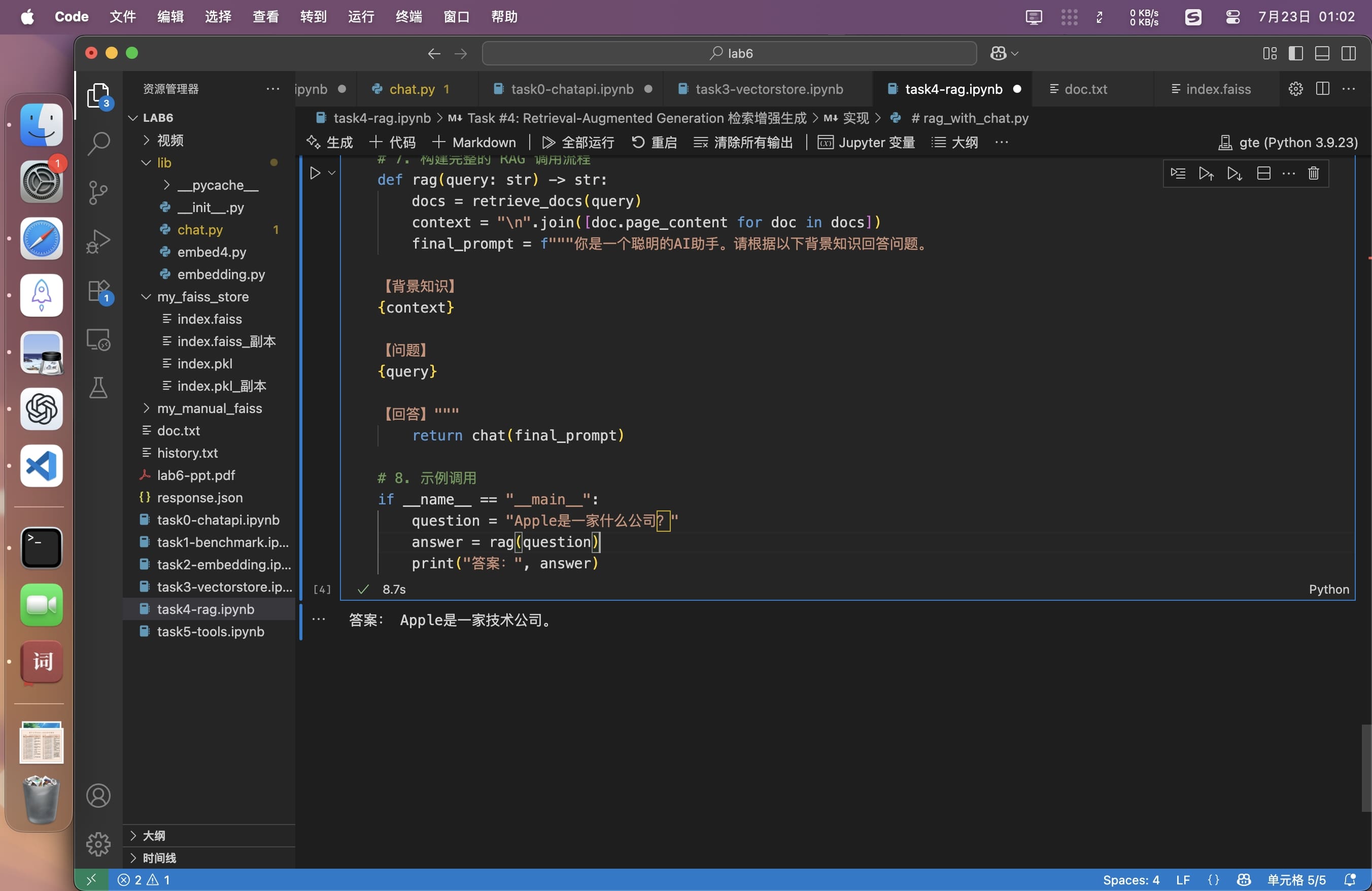
def rag(query: str) -> str:
docs = retrieve_docs(query)
context = "\n".join([doc.page_content for doc in docs])
final_prompt = f"""你是一个聪明的AI助手。请根据以下背景知识回答问题。
【背景知识】
{context}
【问题】
{query}
【回答】"""
return chat(final_prompt)
if __name__ == "__main__":
question = "Apple是一家什么公司?"
answer = rag(question)
print("答案:", answer)
# calculator_api.py
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route("/")
def home():
return "Calculator API is running!"
@app.route("/calculate", methods=["POST"])
def calculate():
data = request.get_json()
expression = data.get("expression", "")
try:
result = eval(expression)
return jsonify({"result": result})
except Exception as e:
return jsonify({"error": str(e)}), 400
if __name__ == "__main__":
print("Calculator API starting on port 8641...")
app.run(host="0.0.0.0", port=8641)
Task #5: 大语言模型工具增强
目标
- 理解大模型工具调用的原理
- 实现大模型工具调用
实验内容
- 用Python实现一个计算器函数(支持加减乘除)
- 基于Python Flaskapi和Uvicorn将上面这个计算器包装成Local RESTFUL API(比如端口8641)
- 设计相应的工具描述,便于大模型理解并调用工具
- 实现工具调用流程,能够满足用户的复杂计算请求(例如 我想知道129032910921*188231”)
- 设计一组用例,对比工具增强前后大模型的能力差异
参考文档
- 开源大模型ChatGLM3的工具增强实现 https://zhuanlan.zhihu.com/p/664233831
- Minimax的Function Call的概念 https://platform.minimaxi.com/document/guides/chat-model
准备知识
大模型调用工具,其实就是让大模型“在response中挖空”,然后请求工具url,把这个空填上。
工具的实现
需要使用flask将工具映射到一个本地端口,这样大模型就可以调用它了。
实现后还需要启动它。需要注意的是,在终端中"python"可能alias到了奇怪的位置,导致直接python xxx并不是在conda环境中。建议check一下which python。启动calculator_api后,应该输出
Calculator API starting on port 8641...
* Serving Flask app 'calculator_api'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8641
* Running on http://192.168.1.8:8641
Press CTRL+C to quit
127.0.0.1 - - [23/Jul/2025 01:23:41] "POST /calculate HTTP/1.1" 200 -
import json
import requests
from lib.chat import chat
# 工具调用函数
def call_calculator_tool(expression: str):
try:
response = requests.post("http://localhost:8641/calculate", json={"expression": expression})
return response.json()["result"]
except Exception as e:
return f"计算器调用失败: {e}"
# 用户输入
user_input = "我想知道129032910921 * 188231是多少"
# 构造 system prompt
prompt = f"""
你是一个智能助手,拥有一个名为 calculator 的工具,它可以执行数学表达式计算(如加减乘除)。
如果用户的问题涉及复杂计算,请输出如下格式:
TOOLCALL calculator {{ "expression": "表达式" }}
否则直接回答。
现在用户的问题是:
{user_input}
"""
response = chat(prompt)
# 检查是否触发 TOOLCALL
if response.startswith("TOOLCALL calculator"):
try:
json_str = response[len("TOOLCALL calculator"):].strip()
tool_args = json.loads(json_str)
expression = tool_args["expression"]
result = call_calculator_tool(expression)
print(f"计算结果是:{result}")
except Exception as e:
print(f"调用工具失败: {e}")
else:
print("模型回答:", response)